
Scientia Conditorium
[혼만파] 혼공학습단 14기_혼자 만들면서 공부하는 파이썬 4주차 본문
[혼만파] 혼공학습단 14기_혼자 만들면서 공부하는 파이썬 4주차
[기본 숙제] Ch.07(07-3) 시가총액 데이터 시각화하기
결과 화면

역시 데이터 시각화하기 전에 한번 가공해줘야 하는데, 그 부분을 빼먹어서 시간이 오래걸렸다.
책 p.241에 나오는 top_kospi_company 함수가 핵심이였다.
그나저나 책에는 삼성전자 시가총액이 353조원이였는데 25년 8월 3일 기준으로 408조원으로 올랐다니 이럴수가...
[추가 숙제] Ch.07 미니프로젝트(p.246) ETF 데이터 시각화하기
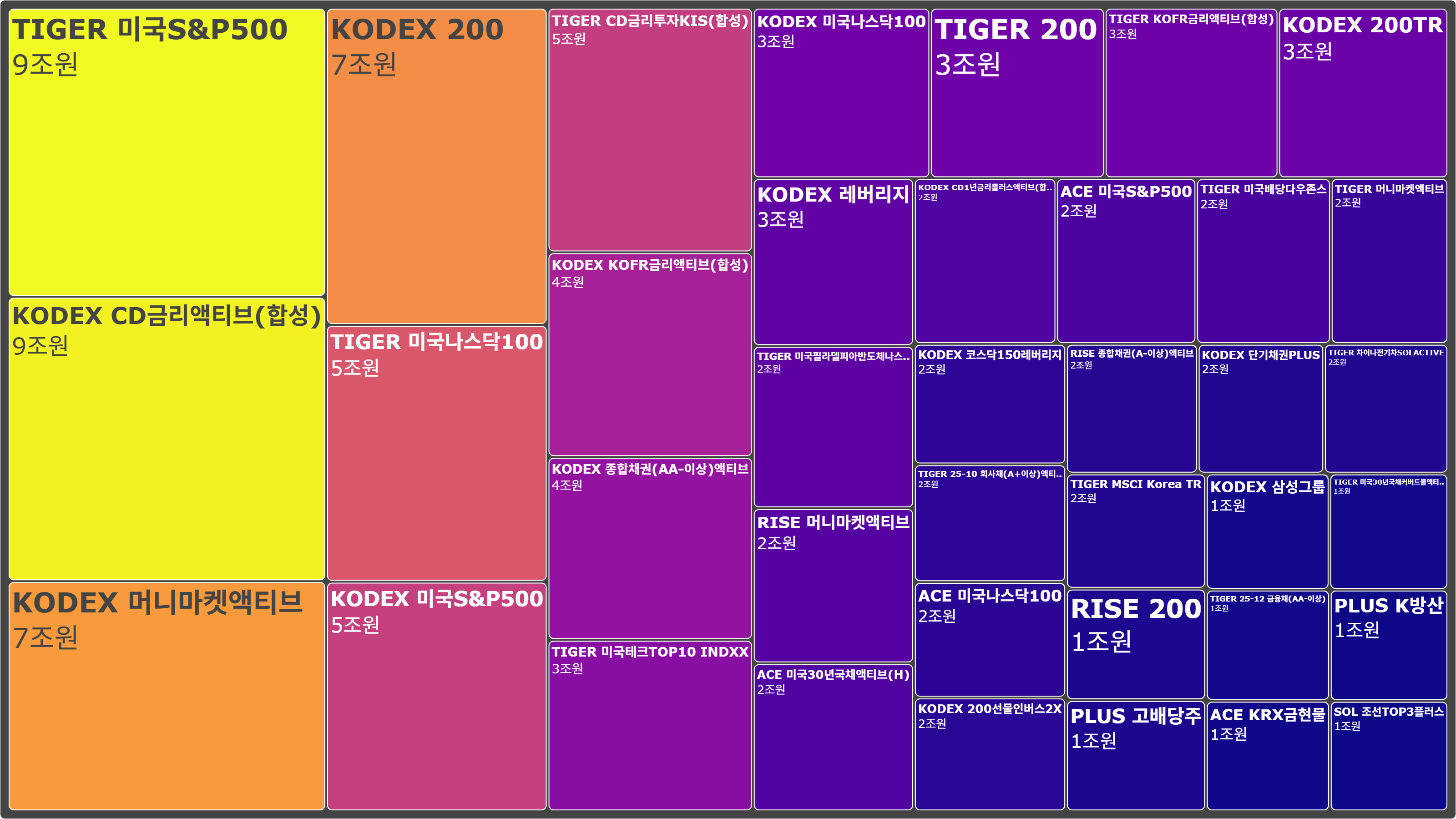
이번건 조금 어려웠다.
파이썬 코드에 익숙하지 않아서 어떤 부분을 수정해야하는지 감이 잘 오지 않았다.
그러나 어쨌든 기존 코드에서 조금만 수정하면 됐다.
지난 3주차 포스팅에서 table_to_dataframe 함수에서 마지막 열을 삭제하는 코드가 있다.
바로 df_raw = df_raw.iloc[:,:-1] 부분인데 마지막 열을 삭제하고 남은 열을 반환하는 코드다.
이 코드가 있으면 ETF 정보를 가져올 때 마지막 열 '시가총액(억)' 부분을 가져올 수 없는 것이다.
또 하나 시가총액 시각화 코드와 다른 점은 top_kospi_company 함수에서 첫 번째 df_raw["시가총액"] 이 아니라
df_raw["시가총액(억)"] 으로 써야한다는 점이다.
따라서 전체 수정 코드는 다음과 같다.
import json
from pathlib import Path
from playwright.sync_api import Browser, Page, Playwright, sync_playwright
import pandas as pd
WORK_DIR = Path(__file__).parent
OUT_DIR = WORK_DIR / "output"
OUT_1_3 = OUT_DIR / f"{Path(__file__).stem}.json"
def run_playwright(slow_mo: float = None) -> tuple[Playwright, Browser, Page]:
play: Playwright = sync_playwright().start() # Playwright 객체 생성
browser: Browser = play.chromium.launch( # Broswer 객체 생성
args=["--start-maximized"], # 웹 브라우저 최대화
headless=False, # 헤드리스 모드 사용 여부
slow_mo=slow_mo, # 자동화 처리 지연 시간
)
page: Page = browser.new_page(no_viewport=True) # Page 객체 생성
return play, browser, page
def goto_market_cap(page: Page):
page.goto("https://finance.naver.com")
page.get_by_role("link", name="국내증시").click()
page.get_by_role("link", name="ETF", exact=True).first.click()
def parse_table_kospi(page: Page) -> tuple[list, list]:
tag_table = page.locator("table")
tag_thead = tag_table.locator("tbody > tr > th")
header = tag_thead.all_inner_texts()
tag_tbody = tag_table.locator("tbody > tr")
body = [tr.locator("td").all_inner_texts() for tr in tag_tbody.all()]
return header, body
def clean_white_space(text: str) -> str:
return " ".join(text.split())
def table_to_dataframe(header: list, body: list) -> pd.DataFrame:
df_raw = pd.DataFrame(body, columns=header)
df_raw = df_raw.dropna(how="any")
#df_raw = df_raw.iloc[:, :-1] #여기를 주석처리해야 ETF 마지막 열 시가총액(억) 열 정보를 사용할 수 있다!
for col in df_raw.columns:
df_raw[col] = df_raw[col].apply(clean_white_space)
return df_raw
def top_kospi_company(df_raw: pd.DataFrame, prop: float) -> pd.DataFrame:
df_raw["시가총액"] = df_raw["시가총액(억)"].str.replace(",", "").astype(int) #여기가 시가총액 부분과 다른 점! 주의!
df_raw["조단위"] = df_raw["시가총액"] / 10_000
df_raw = df_raw.sort_values("시가총액", ascending=False)
df_raw["누적비율"] = df_raw["시가총액"].cumsum() / df_raw["시가총액"].sum()
df_sliced = df_raw.loc[df_raw["누적비율"] <= prop]
return df_sliced.filter(["종목명", "시가총액", "조단위", "누적비율"])
if __name__ == "__main__":
OUT_DIR.mkdir(exist_ok=True)
play, browser, page = run_playwright(slow_mo=1000)
goto_market_cap(page)
header, body = parse_table_kospi(page)
dumped = json.dumps(dict(header=header, body=body),
ensure_ascii=False, indent=2)
OUT_1_3.write_text(dumped, encoding="utf-8")
browser.close()
play.stop()
parsed = json.loads(OUT_1_3.read_text(encoding="utf-8"))
header, body = parsed["header"], parsed["body"]
df_raw = table_to_dataframe(header, body)
df_raw.to_csv(OUT_DIR / f"{Path(__file__).stem}.csv", index=False)
df_raw = pd.read_csv(OUT_DIR / f"{Path(__file__).stem}.csv")
df_top = top_kospi_company(df_raw, 0.5)
df_top.to_csv(OUT_DIR / "ch07_new.csv", index=False)
귀찮아서 함수 이름을 바꾸지 않았지만 ETF 데이터 시각화 역시 기존 코드를 조금만 바꾸면 쉽게 뽑아낼 수 있었다.
'서평 > IT-책' 카테고리의 다른 글
| [혼만파] 혼공학습단 14기_혼자 만들면서 공부하는 파이썬 6주차 (0) | 2025.08.15 |
|---|---|
| [혼만파] 혼공학습단 14기_혼자 만들면서 공부하는 파이썬 5주차 (3) | 2025.08.10 |
| [혼만파] 혼공학습단 14기_혼자 만들면서 공부하는 파이썬 3주차 (1) | 2025.07.21 |
| [혼만파] 혼공학습단 14기_혼자 만들면서 공부하는 파이썬 2주차 (2) | 2025.07.12 |
| [책리뷰] 모두의 딥러닝 (2) | 2025.07.11 |
'서평/IT-책' Related Articles
more


