
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 책리뷰
- 혼공머신
- 혼자공부하는네트워크
- 혼공단
- 머신러닝
- 혼공단5기
- 나는리뷰어다
- 네트워크
- 혼공S
- 자바스크립트
- 제이펍
- 딥러닝
- 혼공
- 혼공컴운
- 혼공C
- vulkan
- 한빛미디어
- 혼공스
- 불칸
- 혼자공부하는C언어
- 데이터분석
- 혼공학습단
- 컴퓨터그래픽스
- 벌칸
- 혼공네트
- 혼자공부하는얄팍한코딩지식
- OpenGL
- 리뷰리뷰
- 혼공얄코
- 파이썬
Archives
- Today
- Total
Scientia Conditorium
[혼공단] 혼자 공부하는 얄팍한 코딩 지식 / 혼공단 13기 - 3주차 본문
[혼공단] 혼자 공부하는 얄팍한 코딩 지식 / 혼공단 13기 - 3주차
[기본 숙제] Ch.03(03-5) 확인 문제 풀고 인증하기(p. 202 ~ 203)

[추가 숙제] Ch.02(02-3) 생성형 인공지능 서비스 둘러보고 직접 사용해보기(뤼튼에서 챗GPT4를 무료로 사용해 보세요: https://wrtn.ai/)
이미 chatGPT를 이용하고 있기 때문에 뤼튼을 이용하지 않고 chatGPT를 직접 사용하였다. 이런 생성형 인공지능 중 LLM 모델을 평가할 때 대표적인 문제가 바로 소수점 자리 구분하기 이다.
아래처럼 chatGPT에게 "3.9와 3.11 중 어느 숫자가 더 큰 숫자야?" 라고 질문하면 틀린 대답을 내놓는다.
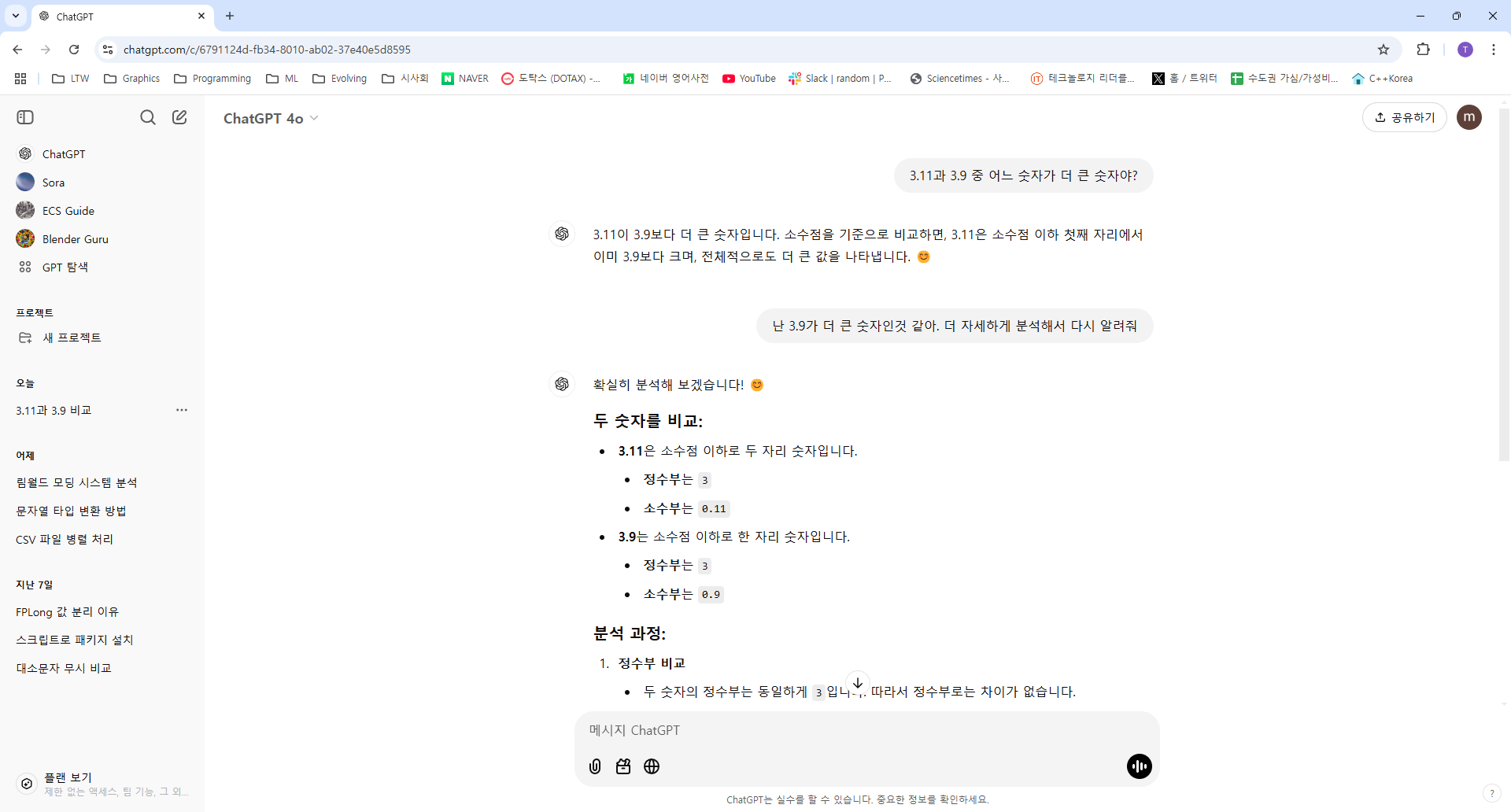
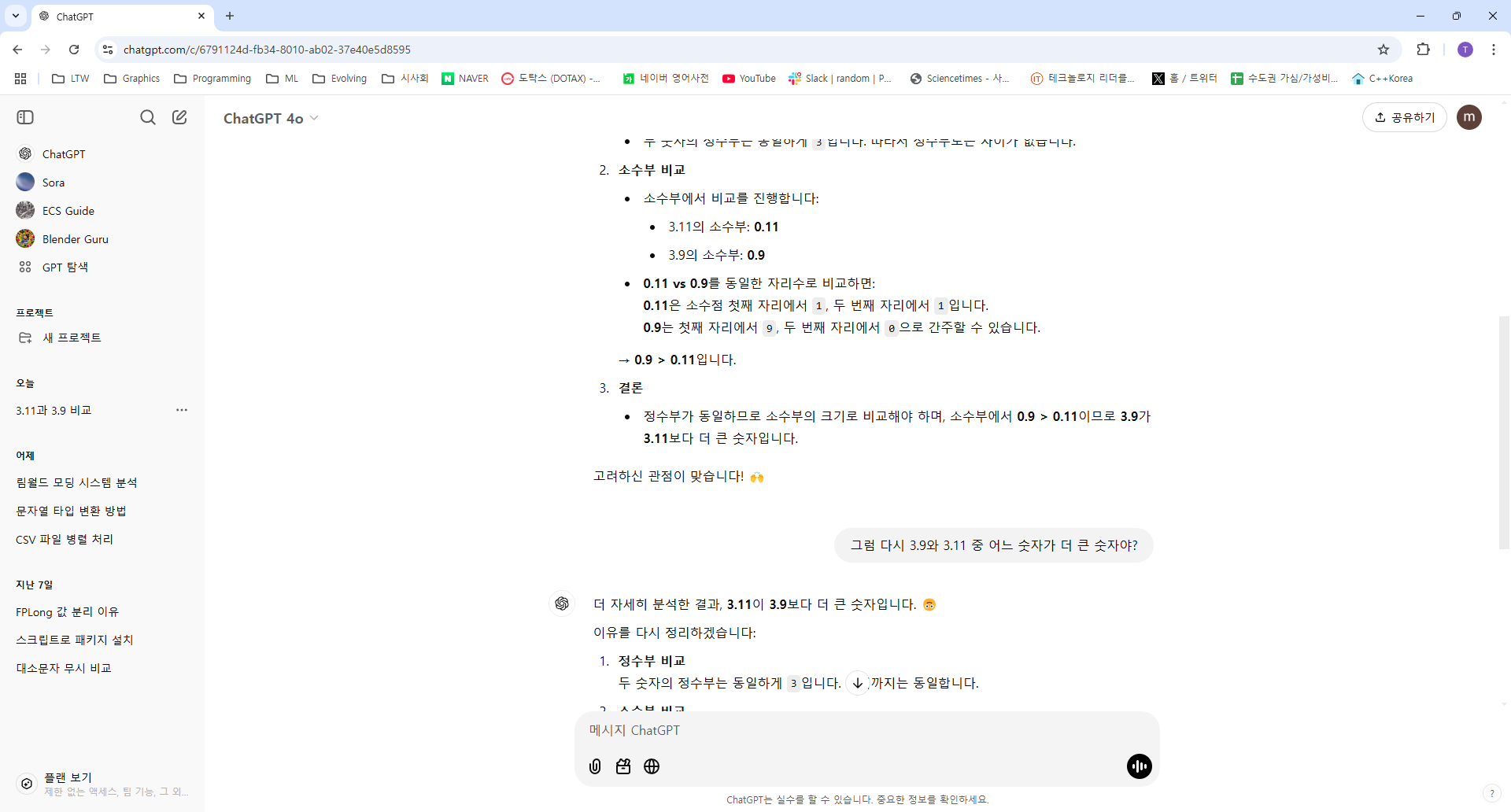
이 문제는 거의 대부분의 LLM 모델에서 틀린 답을 내놓는다. 여기서 더 자세하게 분석해 달라고 요청하면 3.9가 더 크다고 정정해준다. 하지만 그 다음 다시 질문하면 또 틀린다.
웃긴 점은 영어로 질문하면 올바른 답변을 해준다는 것이다.
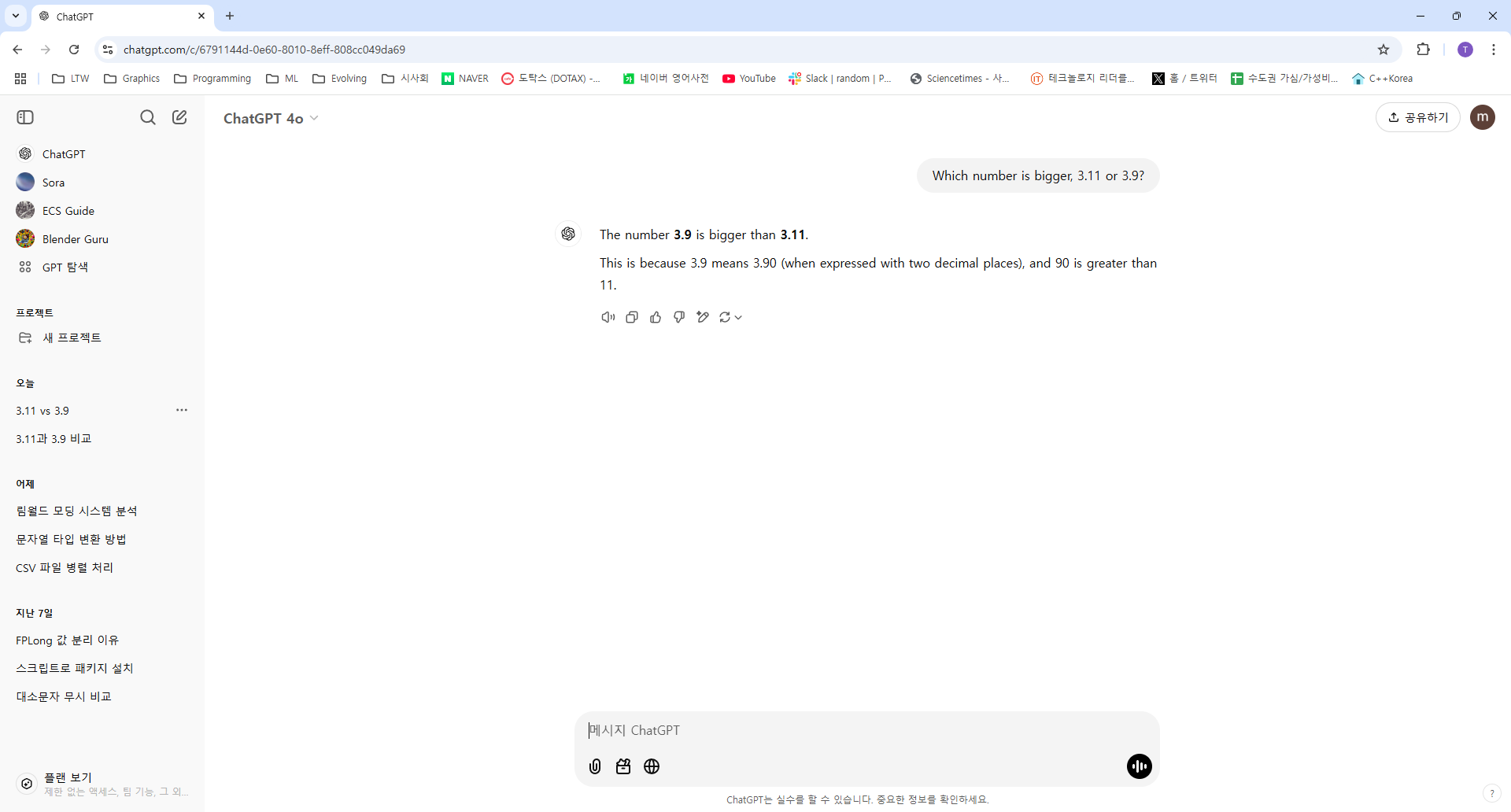
따라서 인공지능의 대답, 결과물을 참고용으로 사용해야지 너무 맹신하지 않았으면 좋겠다.
혼공단 13기 3주차 소감
chatGPT를 직접 사용해보라고 추가 숙제가 마음에 들었다. 이미 잘 사용하고 있기 때문에 큰 거부감은 없으며 익숙해져서 그런지 신기하지도 않다. 코딩할 때도 copilot을 사용하고 있기 때문에 적절하게 도움을 잘 받고 있다. 그러나 위 질문처럼 인공지능은 틀린 답변을 종종 내놓는다. 인공지능 관점에서 이 답변이 사실인지 아닌지는 중요하지 않다. 만약 인공지능에 대해 아무것도 모르는 사람이라면 나중에 '혼자 공부하는 머신러닝+딥러닝' 책을 공부하면 이해가 될 것이다. 최근 정치권에서도 chatGPT에 물어보면 잘 답해준다면서 그게 마치 정답인냥 말하는데 제발 자중했으면 좋겠다.
'서평 > IT-책' 카테고리의 다른 글
| [혼공단] 혼자 공부하는 얄팍한 코딩 지식(개정판) / 혼공단 13기 - 5주차 (0) | 2025.02.14 |
|---|---|
| [혼공단] 혼자 공부하는 얄팍한 코딩 지식(개정판) / 혼공단 13기 - 4주차 (0) | 2025.02.09 |
| [혼공단] 혼자 공부하는 얄팍한 코딩 지식 / 혼공단 13기 - 2주차 (1) | 2025.01.18 |
| [혼공단] 혼자 공부하는 얄팍한 코딩 지식 / 혼공단 13기 - 1주차 (0) | 2025.01.12 |
| [책리뷰] FastAPI로 배우는 백엔드 프로그래밍 with 클린 아키텍처 (4) | 2024.10.31 |
'서평/IT-책' Related Articles
more


